Bitsmi Blog
Usando Let's Encrypt y Certbot para generar certificados TLS para nginx
Let’s Encrypt es una autoridad de certificación que proporciona certificados TLS de forma gratuita a todo host que lo necesite para securizar las comunicaciones con éste. Si además se utiliza un sistema NOIP como DuckDNS como servidor DNS, se consigue sin costes adicionales tener un servidor publicado en la red aunque no se disponga de IP fija.
Las únicas contrapartidas que tiene son que el host ha de ser accesible desde internet, lo que deja fuera a hosts dentro de intranets, y que la duración del certificado generado es de 3 meses, lo que implica una renovación constante.
Afortunadamente, el proceso de generación y renovación de los certificados se puede automatizar completamente mediante la herramienta Certbot que tiene soporte para multitud de sistemas operativos y plataformas cloud.
En este post se describe el proceso de generación de certificados para un servidor HTTP nginx ubicado en un sistema Ubuntu 20.04 con IP dinámica gestionada por el servicio DuckDNS.
OCP 11 - Language Enhancements (Java Fundamentals - Final modifier)
Introduction
Final modifier can be applied to variables, methods and classes. Marking a:
- Variable final means the value cannot be changed after it is assigned.
- Method or a class means it cannot be overridden (for methods) or extended (for classes).
Declaring final local variables
For final variables there are several aspects to consider.
We do not need to assign a value to the final variable when we declare it. What we have to assure is the a value has been assigned to it before this final variable is used. We will get a compilation error in case we don’t follow this rule. Example which illustrates this:
private void printZooInfo(boolean isWeekend) {
final int giraffe = 5;
final long lemur;
if (isWeekend) lemur = 5;
giraffe = 3; // DOES NOT COMPILE
System.out.println(giraffe+" "+lemur); // DOES NOT COMPILE
}
Here we have two compilation errors:
- The giraffe variable has an assigned value so we can’t assign a new value because it has been declared as final. We will get a compilation error.
- When attempting to use lemur variable we will get a compilation error. If condition isWeekend is false we can’t assign the value to lemur so we will the error the error compilation because a local variable to has to be declared and assigned before using it (despite the fact of being declared as final or not).
When we mark a variable as final it does not mean that the object associated with it cannot be modified. Example to illustrate this:
final StringBuilder cobra = new StringBuilder();
cobra.append("Hssssss");
cobra.append("Hssssss!!!");
We have declared the variable as constant but the content of the class can be modified.
Adding final to Instance and static variables
Instance and static class variables can be marked as final too.
When we mark as final a:
- Instance variable which it means that it must be assigned a value when it is declared or when the object is instantiated (Remember: We can only assign once, like Local Variables). Example to illustrate this:
public class PolarBear { final int age = 10; final int fishEaten; final String name; { fishEaten = 10; } public PolarBear() { name = "Robert"; } public PolarBear(int height) { this(); } }Does this code compile? Yes. Everything. Exercise: Explain why.
- Static variable which it means they have to use static initializers instead of instance initializers. Example to illustrate this:
public class Panda { // We assign a value when we declare the final variable final static String name = "Ronda"; static final int bamboo; static final double height; // DOES NOT COMPILE - Why? Because we do not have assign any value to height variable // It will work because we are initializing a final static variable through an static initializer static { bamboo = 5;}}
Writing final methods
Methods marked as final cannot be overriden by a subclass. This avoids polymorphic behavior and always ensures that it is always called the same version method. Be aware because a method can have abstract or final modifier but not both at the same time.
When we combine inheritance with final methods we always get an error compilation.
We cannot declare a method final and abstract at the same time. It is not allowed by the compiler and of course we will get a compilation error. Example to illustrate this:
abstract class ZooKeeper {
public abstract final void openZoo(); // DOES NOT COMPILE
}
Marking Classes final
A final class is one class that cannot be extended. In fact we will get a compilation error if we tried. Example to illustrate this:
public final class Reptile {}
public class Snake extends Reptile {} // DOES NOT COMPILE
We cannot use abstract and final modifiers at the same time.
public abstract final class Eagle {} // DOES NOT COMPILE
It also happens the same for interfaces.
public final interface Hawk {} // DOES NOT COMPILE
We will get a compilation error in both cases.
Construcción de imágenes de Docker multiplataforma con Buildx
Docker proporciona soporte para crear y ejecutar contenedores en una multitud de arquitecturas diferentes, incluyendo x86, ARM, PPC o Mips entre otras. Dado que no siempre es posible crear las imágenes correspondientes de arquitectura equivalente por cuestiones de disponibilidad, comodidad o rendimiento, la alternativa de poder crearlas desde un mismo entorno crea interesantes escenarios, como la posibilidad de tener un servicio de integración continua encargado de la creación de todas las variaciones para las diferentes arquitecturas cubiertas por una aplicación.
En este artículo se expone la configuración de la herramienta buildx de Docker para la creación imágenes de múltiples arquitecturas en un mismo entorno. En el ejemplo incluido se crearán 2 imágenes para las arquitecturas AMD64 y ARM64 en un entorno basado en Ubuntu Linux AMD64.
Restaurar pendrive bootable
Habitualmente se utilizan pendrives como soporte para la instalación de sistemas operativos mediante la creación de un pendrive bootable. El problema es que después de hacer esto este queda en un estado que no permite su uso para el almacenamiento de datos porque el proceso de conversión a bootable ha creado múltiples particiones y sistemas como Windows no son capaces de reconocerlo correctamente.
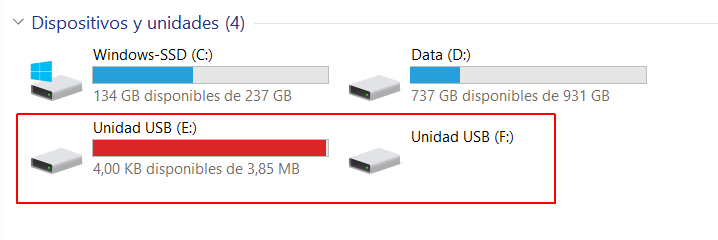
En este post se describe el proceso de restauración de un pendrive bootable a su estado original en Windows.
OCP11 - Understanding Modules
Java Platform Module System or JPMS was introduced in Java 9 as a form of encapsulation package.
A module is a group of one or more packages and a module-info.java file that contain its metadata.
In other words it consists in a ‘package of packages’.
Benefits of using modules:
While using modules in a Java 9+ application is optional, there are a series of benefits from using them:
-
Better access control: Creates a fifth level of class access control that restricts packages to be available to outer code. Packages that are not explicitly exposed through
module-infowill be not available on modules external code. This is useful for encapsulation that allows to have truly internal packages. -
Clear dependency management: Application’s dependencies will be specified in
module-info.javafile. This allows us to clearly identify which are the required modules/libraries. -
Custom java builds: JPMS allow developers to specify what modules are needed. This makes it possible to create smaller runtime images discarding JRE modules that the application doesn’t need (AWT, JNI, ImageIO…).
-
Performances improvements: Having an static list of required modules and dependencies at start-up allows JVM to reduce load time and memory footprint because it allows the JVM which classes must be loaded from the beginning.
-
Unique package enforcement: A package is allowed to be supplied by only one module. JPMS prevents JAR hell scenarios such as having multiple library versions in the classpath.
The main counterpart is not all libraries have module support and, while it is possible it also makes more difficult to switch to a modular code that depends on this kind of libraries. For example, libraries that make an extensive use of reflection will need an extra configuration step because JPMS cannot identify and load classes at runtime.
OCP11 - Local Variable Type Inference
Working with Local Variable Type Inference
After Java 10 we can use the keyword var instead of the type for local variables (like the primitive or the reference type) under certain conditions within a code block.
public void whatTypeAmI {
var name = "Hello";
var size = 7;
}
The formal name of this feature is local variable type inference but we have to consider two main parts for this feature.
OCP11 - Assertions
Assertion is a mechanism that allows you to check assumptions in the code that help you to confirm the proper functioning of the code and that it is free of errors. The following post shows its basic operations and the situations in which its use is appropriate and in which it is not.
An assertion expression is identified by the assert keyword. Its syntax is as follows:
assert <expression> [: <message>]
Where:
- expression: Boolean expression that indicates whether the assumption is satisfied or not. In case it is not fulfilled, an
AssertionErrortype error will be thrown. - message: Optional. If a message is specified in the expression, it will be attached to the produced
AssertionError.
Error al sincronizar repositorio Git con certificado SSL auto-firmado
Descripción del error
El cliente local de Git produce un error de comunicación con el servidor remoto cuando este último tiene un certificado SSL auto-firmado, avisando que la comunicación no es segura.
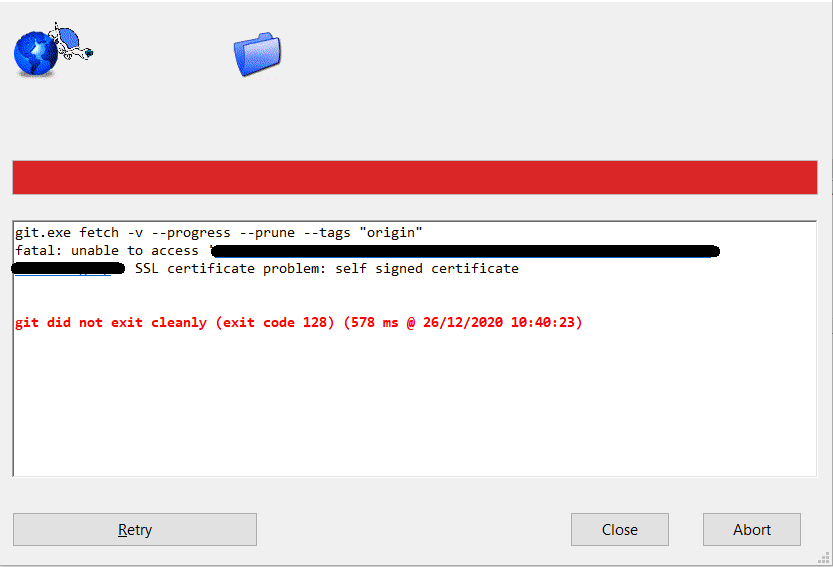
Solución
Es posible indicar a Git que confíe en origen remoto y permita trabajar con el repositorio. Esto se debe hacer sólo si se conoce el repositorio remoto y se confía en él.
Monitorización de sistemas mediante Grafana - 1. Instalación
El monitorizado de sistemas y aplicaciones proporciona un importante mecanismo para el análisis del funcionamiento de estos, permitiendo anticipar situaciones futuras o alertando de problemas que de otra manera quedarían ocultos o difícilmente identificables.
Grafana es una solución que permite el monitorizado completo de sistemas y aplicaciones mediante la recolección de métricas y logs desde multitud de fuentes de datos.
El stack de Grafana cubre todas las fases desde la recolección del dato hasta su visualización gracias a los diferentes componentes que la componen:
- Prometheus: Encargado de la recolección de métricas. Utiliza un modelo Pull de recolección por el cual es el propio Prometheus quien requiere los datos al sistema monitorizado, que debe disponer de un endpoint al cual se pueda conectar. El stack dispone del componente Node-Exporter que proporciona acceso a multitud de métricas al instalarlo en el sistema objeto (CPU, uso de memoria, disco, red…). Es apropiado para la recolección de datos en intervalos de tiempo programados, aunque también proporciona mecanismos para su uso en ejecuciones batch u one-shot.
- Graphite: Encargado de la recolección de métricas. A diferencia de Prometheus, funciona mediante un modelo Push, por lo que es el propio sistema objeto de la monitorización el encargado de enviar los datos a Graphite a través de un endpoint que este provee.
- Loki: Encargado de la recolección de trazas de log. Como Graphite utiliza un modelo Push para publicar los datos en Loki pero afortunadamente en este caso el componente Promtail facilita la tarea encargándose de extraer las trazas de log y dándoles el formato apropiado para su publicación.
- Grafana: Permite la visualización y explotación de métricas y trazas de log accesibles mediante la conexión a diversas fuentes de datos, entre las que se incluyen los mencionados Prometheus, Graphite y Loki, pero que también incluyen plug-ins para la conexión a servicios en la nube como AWS CloudWatch, Azure Monitor, Google Cloud Monitoring, bases de datos relacionales (MySQL, PostgreSQL, MSSSQL…), NoSQL (ElasticSearch, OpenTSBD…) o sistemas de recolección de trazas de log (Jaeger, Zipkin…).
Este es el inicio de una serie de artículos donde se propondrá la construcción de un sistema centralizado de monitorizado de sistemas y aplicaciones con capacidad de análisis de métricas y trazas de log.
Uso de toolchains Maven
Un toolchain en Maven es un mecanismo que permite a los plugins que se ejecutan durante las diferentes fases de construcción de un artefacto acceder a un conjunto de herramientas predefinido de forma general. De esta forma se evita que cada uno de ellos deba definir la composición y ubicación de este conjunto de herramientas y se homogeniza para que en todos los casos sea la misma. Habitualmente este mecanismo se utiliza para proporcionar la especificación de la jdk que será utilizada en el proceso de construcción en los casos que se deba utilizar una implementación diferente a utilizada para ejecutar el propio Maven, pero existe la posibilidad de construir toolchains personalizadas. El uso de las diferentes tipologías de toolchains debe estar soportado por los plugins utilizados. Afortunadamente, plugins básicos como maven-compiler-plugin, maven-javadoc-plugin, maven-surefire-plugin, entre otros, están diseñados para dar soporte a toolchains de tipo jdk, lo que permite definir procesos de construcción para diferentes implementaciones de jdk sin problema.
En este artículo se explicarán los pasos necesarios para definir una toolchain en la instalación local de Maven y de como utilizarla en la construcción de un artefacto.