Bitsmi Blog
Inclusión de recursos zip como dependencias Maven
Maven es una herramienta altamente utilizada en el ecosistema Java para gestionar los módulos y librerías que componen una aplicación, ya sea directamente a través del própio Maven o de otras herramientas, como Gradle, SBT, Ivy, etc., que utilizan los repositorios de este para obtener dichos recursos. A parte de artefactos de tipo jar, war o definiciones pom, Maven también permite gestionar empaquetados de tipo zip en los repositorios. Esto permite gestionar dependencias a recursos estáticos comunes en varios proyectos Maven sin necesidad de duplicarlos en cada uno de ellos, facilitando así su mantenimiento y actualización. En este artículo se muestra de forma genérica como incluir recursos comunes en un proyecto Maven a través de una dependencia y un caso concreto de como aprovechar esto para gestionar paquetes npm de forma local sin tener que hacer uso de un repositorio npm remotoé
Sdkman - The Software Development Kit Manager
SDKMAN! es una herramienta para manejar versiones paralelas de múltiples Kits de Desarrollo de Software en la mayoría de los sistemas basados en Unix. En este post, aunque originalmente está pensando para sistemas Unix veremos su utilización mediante Java en su version 11 en entornos Windows, concretamente con Windows 10.
Proporciona una conveniente Interfaz de Línea de Comando (CLI) y API para instalar, cambiar, eliminar y listar candidatos.
Anteriormente conocido como GVM el Groovy enVironment Manager, fue inspirado por las muy útiles herramientas RVM y rbenv, utilizadas en general por la comunidad Ruby.
Para poder ser utilizando en entornos Windows es neceasario realizar una refacorización del código fuente del script bash original.
Existe una sección (install) en la propia página web dónde se indican los pasos a seguir para su instalación y utilización en entornos Windows.
Para mostrar su uso en Windows 10 se utiliza el Shell de Git Bash mediante el uso de este script get_sdkman_io (ya preparado para funcionar en entornos Windows).
Migrar un repositorio de código Mercurial a Git
En el siguiente artículo se expone el proceso de migración de un repositorio de código gestionado por Mercurial SCM a Git SCM. El proceso se puede llevar a cabo en entornos Linux / Unix o Windows utilizando la consola de comandos Git Bash y adicionalmente herramientas gráficas como Tortoise Hg y Tortoise Git para verificar los resultados.
Incidencias de class loader
En el lenguaje de programación Java, para identificar una clase especifica se tienen en cuenta principalmente 2 cosas: El nombre del package en el que se encuentra y el propio nombre de la clase. Mediante estos 2 valores, el sistema de class loaders de la máquina virtual identifica y carga la diferentes clases según sean necesarias durante la ejecución de una aplicación. Este mecanismo tiene un problema bastante conocido cuando más de una clase con el mismo nombre y package se encuentran contenidas en ficheros jar o directorios diferentes. Este fenómeno es una de las variantes del denominado Jar Hell que en este caso concreto consiste en que no todas las clases pertenecientes al mismo package que son cargadas por el sistema de class loaders proceden de la misma ubicación (directorio de clases o fichero jar), lo que puede ocasionar incompatibilidades o errores inesperados si estas no pertenecen a la misma versión de código.
La especificación de Java define un mecanismo denominado package sealing que puede aplicarse opcionalmente para garantizar que todas las clases pertenecientes a un mismo package son cargadas desde el mismo fichero jar. En caso de que la máquina virtual en un momento determinado intente cargar una clase de un package definido como sellado y esta pertenezca a un fichero jar distinto al del resto de clases del mismo package ya cargadas, se producirá un error advirtiendo de ello. Desafortunadamente, no todas las librerías hacen uso de este mecanismo, por lo que a veces es complicado ver si esta puede ser la causa de un error determinado.
En este artículo se exponen diferentes casuísticas derivadas de este fenómeno y de como identificar la causa de un error de este tipo para poder solucionarlo.
Configurando Raspberry Pi como access Point
En este articulo se expondrán los pasos necesarios para la configuración de la placa Raspberry Pi 3B funcionando con Ubuntu Server a modo de punto de acceso Wifi. Con ello se creará una red inalámbrica independiente que se podrá interconectar con la interfaz ethernet que también incluye la placa y así permitir el intercambio de tráfico de una a otra. Dentro de los posibles usos de esta configuración se encuentran la construcción de una red Wifi para invitados o una red secundaria de servicio para la gestión de dispositivos IOT. Las posibilidades que brinda el sistema operativo para la gestión de la red creada por el punto de acceso permitiría, por ejemplo, el uso del firewall del sistema para limitar o filtrar el tráfico o establecer políticas de acceso de una red a otra.
OCP7 07 – Fork join
OCP7 13 – E/S simultánea
Las llamadas de bloqueo secuencial se ejecutan en una duración de tiempo más larga que las llamadas de bloqueo simultáneo.
OCP7 11 – Hilos (10) – Sincronizadores
El paquete java.util.concurrent proporciona cinco clases que ayudan a las expresiones de sincronización con un objetivo común especial.
Las clases de sincronizador permiten a lo threads bloquearse hasta que se alcanza un determinado estado o acción.
OCP7 11 – Hilos (08) – Paralelismo
Introducción
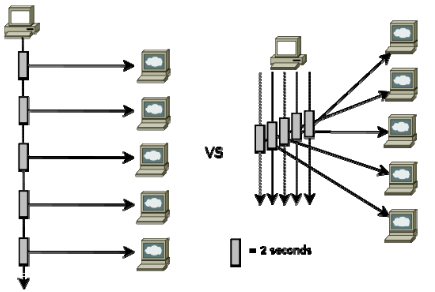
Los sistemas modernos contienen varias CPU. Para sacar partido de la potencia de procesamiento en un sistema es preciso ejecutar tareas en paralelo en varias CPU.
Divide y vencerás. Una tarea se debe dividir en subtareas. Debe intentar identificar aquellas subtareas que se puedan ejecutar en paralelo.
-
Puede ser difícil ejecutar algunos problemas como tareas paralelas.
-
Algunos problemas son más sencillos. Los servidores que soportan varios clientes pueden usar una tarea independiente para manejar cada cliente.
-
Se debe tener cuidado con el hardware. La programación de demasiadas tareas paralelas puede afectar de forma negativa al rendimiento.
Recuento de CPU
Si las tareas requieren muchos cálculos, al contrario de operaciones que generan muchas E/S, el número de tareas paralelas no debe superar en gran cantidad el número de procesadores del sistema.
Puede detectar el número de procesadores de forma sencilla en Java:
int count = Runtime.getRuntime().availableProcessors();
Sin paralelismo
Los sistemas modernos contienen varias CPU. Si no aprovechan los threads de alguna forma, sólo se utilizará una parte de la potencia de procesamiento del sistema.
Definición de etapa
Si tiene una gran cantidad de datos que procesar pero solo un thread para procesar dichos datos, se utilizará una CPU.
Como ejemplo el procesamiento de una matriz podría ser una tarea simple, como buscar el valor más alto en la matriz. Entonces, en un sistema de cuatro CPU, debe haber tres CPU inactivas mientras se procesa la matriz.
Paralelismo naive
Una solución paralela simple divide los datos que se van a procesar en varios juegos en un juego de datos para cada CPU y un thread para procesar cada juego de datos.
División de datos
Siguiendo el ejemplo de la matriz (como gran juego) se divide en cuatro subjuegos de datos, uno para cada CPU.
Ello implica que se crea un thread por CPU para procesar los datos.
Tras el procesamineto de los subjuegos de datos, los resultados se tendrán que combinar de una forma significativa.
Hay distintas forma de subdividir el juego de datos grande que se va a procesar.
- Se usaría demasiada memoria para crear una matriz por thread que contenga una copia de una parte de la matriz original.
- Cada matriz puede compartir una referencia a una única matriz grande pero solo acceder a un subjuego de una forma con protección de hread no bloqueante.
Java Platform Debug Architecture
La Java Platform Debug Architecture o JPDA es la arquitectura que implementa los mecanismos de debug dentro de la JVM. Se trata de una arquitectura multicapa formada por varios componentes:
- Java Debug Interface (JDI): Define la interfaz necesaria para implementar debuggers que se conectarán a la JVM a fin de enviar las diferentes ordenes que se produzcan durante la sesión de debug. Las funcionalidades de debug de los diferentes IDE son ejemplos de front-end que implementan esta interfaz.
- Java VM Tooling Interface (JVM TI): Define los servicios que permiten instrumentalizar la JVM. Esto va desde la monitorización, la manipulación de código en caliente, la gestión de threads de ejecución, el debug de código y otras muchas funciones más. Todo ello se consigue mediante el uso de los denominados agents nativos que es especifican durante el arranque de la JVM mediante el flag
-agentlib:<nombre librería>. En el caso concreto del debug, se utiliza el JWPD agent para procesar las peticiones que se envían desde el front-end del debugger. Los servicios implementados por el JWPD agent en esta capa forman el back-end del debugger que se conecta directamente con el proceso en ejecución de la JVM que está siendo debugado. - Java Debug Protocol (JDWP): Define el protocolo de comunicación entre los procesos front-end y el back-end del debugger a través de varios canales de comunicación que incluyen socket y memoria compartida.
En este artículo se muestra una visión práctica de como configurar la conexión a la JVM para poder las depurar aplicaciones que se ejecuten sobre ella.