Bitsmi Blog
Discusión - Fork vs Branch en Git
Conceptos
La diferencia conceptual entre forking y branching viene dada por desarrollo divergente vs convergente:
-
Concepto de Forking Se refiere al proceso de generar una copia exacta del repositorio origen a uno nuevo en ese instante temporal. Es una copia física real y diferente, la operativa surge para realizar separaciones reales y crear nuevas lógicas bajo una base común, se asume que es poco probable que vuelvan a reunirse con el parent.
-
Concepto de Branching Se refiere a generar un copia del repositorio dentro del mismo repositorio origen, un pointer. Las ramas son espacios temporales sobre los que cuales realizar desarrollos nuevos o cambios. Su objetivo es volver a converger con el repositorio siempre.
La diferencia conceptual es el scope de la copia (copia separada del parent o dentro de éste) y vida (vida independiente contra tiempo de vida efímero).
La razón de la diferencia parece ser la necesidad de controlar quién puede o no realizar push de código a la rama principal, la práctica del forkeo es más común en el open source cuando los posibles colaboradores no tienen permisos sobre el repositorio original, de ahí la copia que genera otro repositorio de facto y luego la posibilidad de converger con el parent o no.
Gestión de máquinas virtuales a través de Vagrant
Vagrant es una herramienta proporcionada por la empresa HashiCorp que permite la construcción y la gestión de máquinas virtuales de forma configurable y reproducible. Esto significa que se podrá crear un arquetipo que defina qué los componentes que forman la máquina virtual y de cómo se ejecuta esta que fácilmente se podrá distribuir para su reproducción en diferentes entornos.
Un caso de uso básico es la creación de una máquina virtual con todos los componentes de un entorno de desarrollo destinado a que los miembros de un equipo ejecuten de forma local, cada uno con su instancia propia. La distribución del arquetipo de definición de la máquina virtual o box permitirá a cada uno de ellos disponer de un entorno estandarizado igual para todos ellos. Con esto se consigue ahorrar tiempo y evitar errores, dado que la configuración sólo se realiza una única vez. También se consigue propagar los cambios que se realicen en dicho entorno de una forma ordenada y documentada, ya que los cambios se realizan directamente en el arquetipo, que además puede ser gestionado por un sistema de control de versiones.
En el presente artículo se presenta una guía inicial de la gestión de máquina virtuales mediante Vagrant, desde la creación de la box, su ejecución y gestión de los recursos asociados.
OCP7 11 – Hilos (04) – ReentrantReadWriteLock
Nota: Los ejemplos mostrados en este artículo suponen la utilización de arquitecturas de CPU que soportan operaciones de definición y comparación atómicas (operaciones Compare And Swap), como por ejemplo los procesadores x86 o Sparc actuales. En este caso las operaciones lock / unlock serán operaciones no bloqueantes. Otras arquitecturas que no soporten esta funcionalidad pueden requerir alguna forma de bloqueo interno por parte de la plataforma.
Paquete java.util.concurrent.locks
El paquete java.util.concurrent.locks es un marco para bloquear y esperar condiciones que es distinto de las supervisiones y sincronización incorporadas.
Creación de una image base para Raspberry Pi
El primer paso para trabajar con una Raspberry Pi siempre es copiar la imagen del sistema operativo en una tarjeta SD y configurar dicho sistema creado usuarios, configurando la red… Si se tienen múltiples dispositivos, esto significa repetir los mismos pasos una y otra vez con las configuraciones comunes.
La siguiente guía describe los pasos a seguir para la creación de la imagen base de una instalación de sistema operativo para Raspberry Pi que pueda ser instalada en múltiples dispositivos y proporcione todas las aplicaciones y configuraciones comunes a todas ellos. Esto incluye la configuración de red, la creación de una cuenta de usuario administrador que centralice la gestión del sistema y la configuración del acceso remoto para dicho usuario de forma remota a través de SSH.
Con ello se pretende ahorrar tiempo y simplificar el mantenimiento de todas las instalaciones, ya que los cambios se harán una sola vez para todos los dispositivos.
CRLF end of line problems in Git
Sometimes a new problem could appear regarding the end of line on files using an IDE (like IntelliJ for example) when doing a Commit&Push into Master through Git.
When this situation happens a new window may popup:
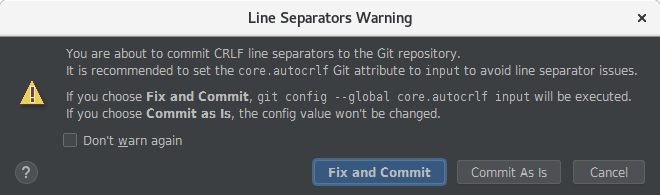
It is recommended the use of the option “commit as it is” by default.
Be sure to uncheck the setting ‘Warn if CRLF line separators are about to be commited to avoid the warning popup’ in case of using the IntelliJ IDE.
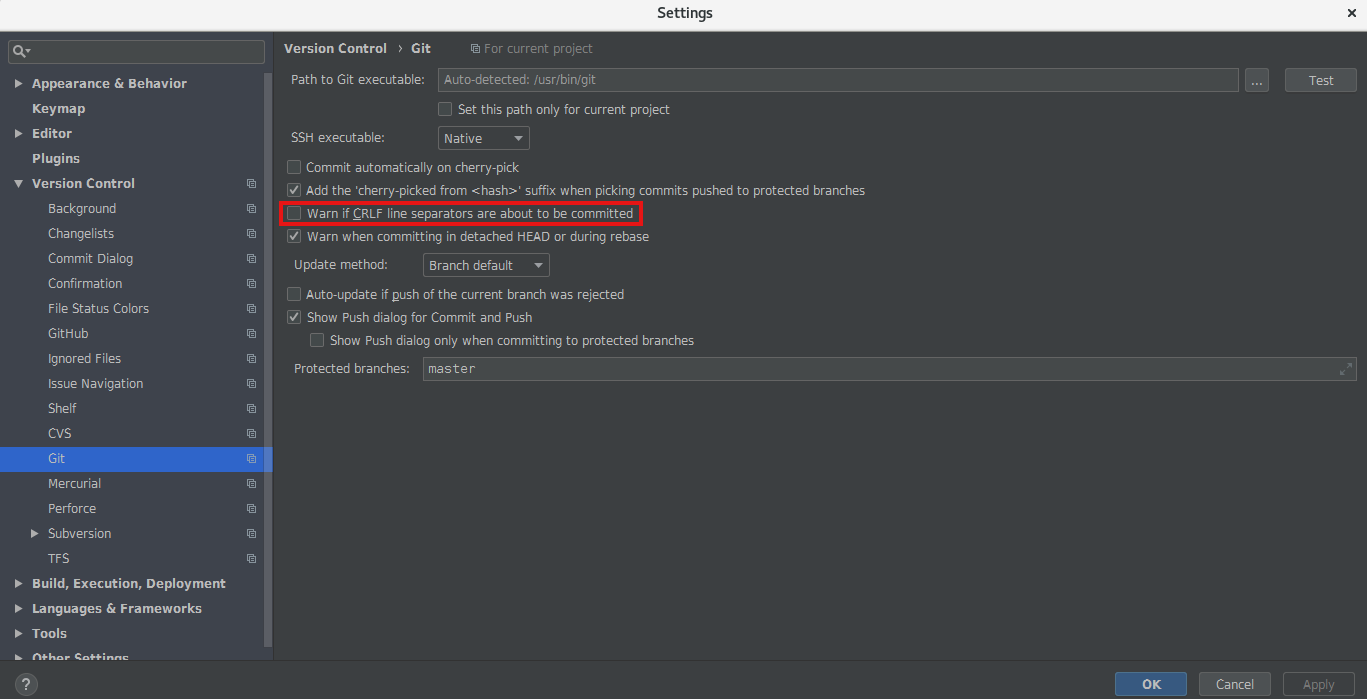
To prevent git from automatically changing the line endings on your files in general is enough running this command:
git config --global core.autocrlf false
BUt a general solution that force one customized configuration is the creation of a new file in the root folder of the project called .gitattributes.
This is its content:
* text eol=crlf working-tree-encoding=UTF-8
*.java text eol=crlf working-tree-encoding=UTF-8
*.xml text eol=crlf working-tree-encoding=UTF-8
*.properties text eol=crlf working-tree-encoding=UTF-8
*.jsp text eol=crlf working-tree-encoding=UTF-8
*.sql text eol=crlf working-tree-encoding=UTF-8
It’s important to point out that this configuration can be changed and adapted to a different one depending on the necessities of the project.
More references
NoClassDefFoundError en la inicialización de una clase Java
Los bloques de código estático en el lenguaje de programación Java són un mecanismo de inicialización de los recursos estáticos de una clase que se ejecuta en el momento en que se interactua con dicha clase por primera vez. Un fallo producido dentro de dichos bloques estáticos puede provocar errores inesperados en la ejecución del programa. En este post se habla de una de la posibles consecuencias de un error de este tipo y de cómo puede ser identificado.
Introducción al problema
Cuando la máquina virtual de Java ejecuta el código de una aplicación, el sistema de Classloaders es el encargado de recuperar e inicializar las clases incluidas en el classpath según se van requiriendo.
El proceso de carga de una clase comprende tanto la lectura del fichero *.class correspondiente cómo la inicialización de esta, lo que incluye:
- Inicialización de miembros estáticos de la clase (variables, clases anidadas…)
- Ejecución de bloques estáticos de inicialización
Por ejemplo, en el seguiente de código define la clase StaticResource que ejecuta un código de inicialización dentro de un bloque static
en el mismo momento en que la máquina virtual carga la clase.
public class StaticResource
{
/* Ejecutado durante la carga de la clase */
static {
System.out.println("INICIALIZACIÓN StaticResource");
// Puede lanzar una RuntimeException
initializeStatic();
}
public static String getResourceName(int index)
{
System.out.println("GET RESOURCE NAME " + index);
return "Resource " + index;
}
private static void initializeStatic()
{
throw new RuntimeException("Error en la inicialización de StaticResource");
}
}
Cómo se puede ver, es perfectamente posible que el código del bloque static lance un error. Este hecho hace que la inicialización de toda la clase falle y por consiguiente, la carga de esta si no se trata correctamente el error.
Análisis del error
Para analizar las trazas producidas por una situación así, se dispone del código expuesto abajo. En el se llama al método estático
StaticResource.getResourceName varias veces para mostrar los efectos de un fallo de este tipo:
public static void main(String... args)
{
try {
String resourceName = StaticResource.getResourceName(1);
System.out.println("RESULT 1: " + resourceName);
}
catch(Throwable e){
System.err.println("ERROR 1: " + e.getMessage());
e.printStackTrace();
}
// ...
try {
String resourceName = StaticResource.getResourceName(1);
System.out.println("RESULT 2: " + resourceName);
}
catch(Throwable e){
System.err.println("ERROR 2: " + e.getMessage());
e.printStackTrace();
}
}
Cómo resultado de la ejecución del código anterior se obtienen las siguientes trazas:
INICIALIZACIÓN StaticResource
ERROR 1: null
java.lang.ExceptionInInitializerError
at MainProgram.main(MainProgram.java:7)
Caused by: java.lang.RuntimeException: Error en la inicialización de StaticResource
at StaticResource.initializeStatic(MainProgram.java:44)
at StaticResource.<clinit>(MainProgram.java:33)
... 1 more
ERROR 2: Could not initialize class StaticResource
java.lang.NoClassDefFoundError: Could not initialize class StaticResource
at MainProgram.main(MainProgram.java:18)
En ellas se puede observar el siguiente comportamiento:
- La primera vez que se llama al método
getResourceName, la máquina virtual intenta cargar e inicializar la clase asociadaStaticResourcey cómo resultado del error producido en el bloque de incializació estático, se produce un error de tipojava.lang.ExceptionInInitializerError - El error es capturado por el bloque try/catch y se prosigue con la ejecución del programa. NOTA: Aquí se ha intentado simular el caso que el error
sea suprimido por algun tipo de sistema de tratamiento de errores o por un catch silencioso, es decir, que no propague el error. Se trata de una
mala práctica hacer catch de
java.lang.Errordado que representan errores fatales en la ejecución. - Las posteriores llamadas al método
getResourceNamedan como resultado un error de tipojava.lang.NoClassDefFoundError. Este tipo de errores ocurre cuando una clase en particular está presente en tiempo de compilación pero no lo está en tiempo de ejecución y esto es justo lo que ha pasado: La clase ha fallado y la máquina virtual no es capaz de cargar la definición en posteriores accesos, por lo que a efectos prácticos es como si esta no existiera, aunque el mensaje que acompaña al error nos da una pista de que ha sucedido por un error en la inicialización de la clase:Could not initialize class StaticResource.
Corregir y prevenir el error
Segun lo visto en el apartado anterior, en los casos que se produce un error de tipo java.lang.NoClassDefFoundError debido a una inicialización fallida de una
clase, esta irá acompañada de un error de tipo java.lang.ExceptionInInitializerError anterior. En caso de que no se pueda identificar este último en las trazas de log
de la aplicación, es posible que se tenga que revisar los diferentes niveles del código implicado buscando una posible supresión del error, cómo por ejemplo un catch silencionso,
o bien añadir nuevas trazas de log que permitan descubrir la existencia del error. Una vez se tiene la certeza de que se tratade un error de incialización, se deberá identificar
la causa del error y proceder en consecuencia, por ejemplo, realizando las siguientes modificaciones:
- Utilizar bloques try/catch: Si se trata de un error recuperable, se puede ejecutar el código alternativo de inicialización dentro del bloque catch
- Propagar el error adecuadamente: Si se trata de un error fatal, se debe asegurar que el error de inicialización se propague correctamente por los diferentes
niveles del
stacktracehasta la parte del código encargada de reportarlo e incluso permitir la finalización de la la ejecución del programa. - Registrar el error: Se debe poder identificar el primer error
java.lang.ExceptionInInitializerErrorrápidamente una vez sucede y por ellos es muy importante que las trazas del error se reporten en el sistema de alertas adecuando (Fichero de log especifico, plataforma de alertas del sistema…) de una forma clara y entendible. - Revisar la idoneidad de la inicialización estática: Se debe considerar la posibilidad de mover el bloque de código problemático de la inicialización estática de la clase, por ejemplo, convirtiendolo en código no estático que se ejecute durante la instanciación de objetos de dicha clase, o bien mediante una inicialización diferida que se ejecute una sóla vez. El código de esto último se muestra a continuación:
public class StaticResource
{
public static String getResourceName(int index)
{
System.out.println("GET RESOURCE NAME " + index);
return "Resource " + index;
}
public static void initializeStatic()
{
// En el siguiente código se puede producir un error
// ...
}
}
// ...
public static void main(String... args)
{
try {
// Ejecutado una sóla vez
String resourceName = StaticResource.initializeStatic();
}
catch(Throwable e){
System.err.println("INITILIZATION ERROR: " + e.getMessage());
e.printStackTrace();
/* En este caso, si la inicialización no es correcta, no tiene sentido seguir
* y por ello se termina la ejecución de la aplicación
*/
System.exit(1);
}
// ...
String resourceName = StaticResource.getResourceName(1);
System.out.println("RESULT: " + resourceName);
}
Aplanado de estructuras de ficheros con PowerShell
En este post se muestra una implementación de copia plana de los contenidos de un árbol de directorios determinado mediante un script de PowerShell. Dicho de otra manera, el resultado de la ejecución de este script copiará en un mismo directorio destino todos los ficheros contenidos en un directorio origen y todos sus subdirectorios.
OCP7 11 – Hilos (05) – Variables atómicas y bloqueos de sincronización
En este artículo se exponen los mecanismos básicos que proporciona la plataforma estándar de Java para el acceso y actualización de variables de forma concurrente. Se tratarán los siguientes conceptos:
- Uso de variables atómicas
- Acceso a variables mediante bloqueos de sincronización
OCP7 11 – Hilos (06) – Colecciones con protección de Thread
En general las colecciones de java.util no tienen protección de thread. Para poder utilizar colecciones en modo de protección de thread se debe utilizar uno de los siguientes mecanismos:
- Utilizar bloques de código sincronizado para todos los accesos a una colección si se realizan escrituras.
- Crear un envoltorio sincronizado mediante métodos de biblioteca como
java.util.Collections.synchronizedList(List<T>). Es importante destacar que el hecho de que una Collection se cree con protección thread no hace que sus elementos dispongan de la misma protección de thread. - Utilizar colecciones dentro de java.util.concurrent.
Autenticación en Bitbucket mediante SSH
Esta mini guia expone los pasos a seguir para configurar el acceso en Bitbucket mediante SSH, de forma que no sea necesaria la especificación de las credenciales cada vez que se realice una acción sobre un repositorio hospedado en dicho servicio. Incluye la configuración necesaria para los 2 tipos de repositorio soportados por Bitbucket Git y Mercurial).
Es importante mencionar que la guia está enfocada a entornos Windows aunque los pasos son bastante similares en entornos Linux cambiando las instrucciones de consola por las del entorno de que toque.