Necesidad de un marco Fork-Join
La división de conjuntos de datos en subconjuntos con el mismo tamaño para cada thread de ejecución tiene un par de problemas.
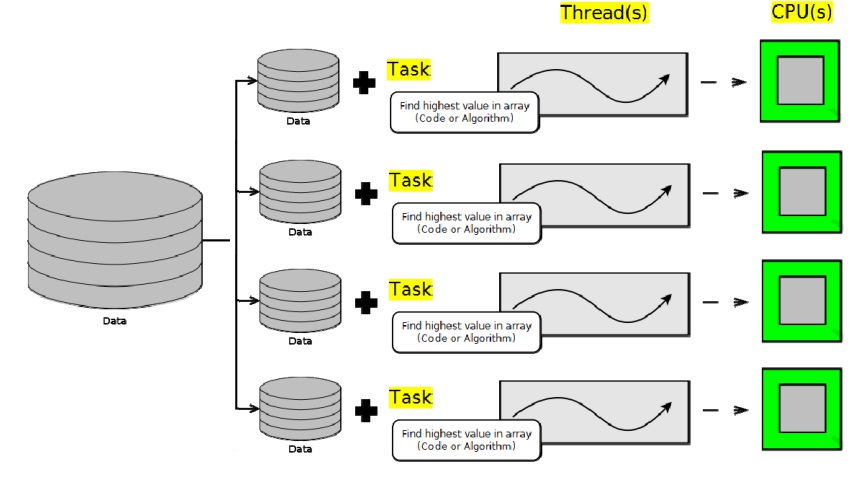
Lo ideal es que todas las CPU se utilicen completamente hasta que la tarea finalice pero:
- Las CPU se pueden ejecutar a diferentes velocidades.
- Las tareas que no son de Java requieren tiempo de CPU y pueden reducir el tiempo del que dispone un thread de Java para la ejecución en una CPU.
- Los datos que se analizan pueden requerir diferentes cantidades de tiempo para el proceso.
Extracción de trabajo
Para mantener varios threads ocupados:
- Divida los datos que se van a procesar en un gran número de subjuegos.
- Asigne los subjuegos de datos a una cola de procesamiento de threads.
- Cada thread tendrá muchos subjuegos en cola.
Si un thread finaliza todos sus subconjuntos pronto, puede "extraer" subconjuntos de otro thread.
Granularidad de trabajo
Al subdividir los datos que se van a procesar hasta que haya más subconjuntos que threads, se está facilitando la "extracción de trabajo".
En la extracción de trabajo, un thread que se queda sin trabajo puede extraer trabajo (un subconjunto de datos) de la cola de procesamientos de otro thread.
Debe determinar el tamaño óptimo del trabajo que se desee agregar a cada cola de procesamiento de thread.
La subdivisión excesiva de datos que se van procesar pueden causar una sobrecarga innecesaria, mientras que una división insuficiente de datos puede dar como resultado una infrautilización de la CPU.
Ejemplo de thread único
int[] data = new int[1024*1024*256]; // 1G Juego de datos muy grande
for(int i = 0; i < data.length; i++) {
// Llenar la matriz con valores
data[i] = ThreadLocalRandom.current().nextInt();
}
int max = Integer.MIN_VALUE;
for(int value : data) {
if(value > max) {
// Buscar de forma secuencial la matriz para el valor mayor.
max = value;
}
}
System.out.println(" Max value found " + max);Paralelo potencial
En este ejemplo hay dos tareas independientes que se podrían ejecutar en paralelo.
La inicialización de la matriz con valores aleatorios y la búsqueda de la matriz del mayor valor posible podrían hacerse en paralelo.
java.util.concurrent.ForkJoinTask
Un objeto ForkJoinTask representa una tarea que se va ejecutar.
-
Una tarea contiene el código y los datos de que se van a procesar. Similar a Runnable o Callable.
-
Un número pequeño de threads en un pool Fork-Join crea y procesa un gran número de tareas.
2.1. ForkJoinTask normalmente crea más instancias ForkJoinTask hasta que los datos que se van procesar se subdividen de forma adecuada. -
Los desarrolladores normalmente utilizan las siguientes subclases:
3.1. RecursiveAction: si una tarea no tiene que devolver un resultado.
3.2. RecursiveTask: si una tarea tiene que devolver un resultado.
Ejemplo de RecursiveTask
// Integer Tipo de resultado de la tarea.
public class FindMaxTask extends RecursiveTask<Integer> {
private final int threshold;
private final int[] myArray; // Datos a procesar
private int start;
private int end;
public FindMAxTask(int[] myArray, int start, int end, int threshold) {
// copy parameters to fields
}
protected Integer compute() {
// Dónde se realiza el trabajo
// Observe el tipo de devolución genérica
// Shown later
}
}Estructura del método compute
protected Integer compute() {
if DATA_SMALL_ENOUGH {
PROCESS_DATA
return RESULT;
} else {
SPLIT_DATA_INTO_LEFT_AND_RIGHT_PARTS
TASK t1 = new TASK(LEFT_DATA);
t1.fork(); // Ejecución asíncrona
TASK t2 = new TASK(RIGHT_DATA);
return COMBINE(
t2.compute(), // Proceso en el thread actual
t1.join() // Bloquear hasta que se termine
);
}
}Ejemplo de compute (por debajo del umbral)
protected Integer compute() {
// (end - start < threshold) -> rango en la matriz
if(end - start < thresold) { // Umbral decidido por el usuario
int max = Integer.MIN_VALUE;
for(int i = start; i <= end; i++) {
int n = myArray[i];
if(n > max) {
max = n;
}
}
return max;
} else {
// split data and create tasks
}
}Ejemplo de compute (por encima del umbral)
Gestión de memoria
Observe que la misma matriz se transfiere a cada tarea pero con diferentes valores de inicio y finalización.
Si el subconjunto de valores que se va a procesar se copiara en una matriz cada vez que se crea una tarea, el uso de la memoria aumentaría rápidamente.
protected Integer compute() {
if(end - start < thresold) {
// find max
} else {
int midWay = (end - start) / 2 + start;
FindMaxTask a1 = new FindMaxTask(myArray, start, midway, thresold); // Tarea para la mitad izquierda de los datos
a.fork();
FindMaxTask a2 = new FindMaxTask(myArray, midway + 1, end, thresold); // Tarea para la mitad derecha de los datos
return Math.max(a2.compute(), a1.join());
}
}Ejemplo de ForkJoinPool
ForkJoinPool se utiliza para ejecutar ForkJoinTask.
Crea un thread para cada CPU en el sistema por defecto.
ForkJoinPool pool = new ForkJoinPool();
FindMaskTask task = new FindMaxTask (data, 0, data.length - 1, data.length/16);
[forkjoin examples](http://bitsmi.com/wp-content/uploads/2020/05/forkjoin.zip "forkjoin examples")
Integer result = pool.invoke(task); // Mediante el invoke el método compute de la tarea se llama automáticamenteRecomendaciones del marco Fork-Join
-
Evite operaciones de bloqueo o E/S.
1.1. Solo se crea un thread por CPU por defecto. Las operaciones de bloqueo evitarán el uso de todos los recursos de CPU. -
Conozca el hardware:
2.1. Una solución ForkJoin se ejecutará de forma más lenta en un sistema de una CPU que una solución secuencial estándar.
2.2. Algunas CPU aumentan la velocidad solo cuándo usan un único núcleo, lo que podría compensar de forma potencial cualquier aumento de rendimiento proporcionado por Fork-Join. -
Conozca el problema.
3.1. Muchos de los problemas tienen una sobrecarga adicional si se ejecutan en paralelo (ordenación paralela, por ejemplo).
Ordenación paralela
Al utilizar Fork-Join para ordenar una matriz en paralelo, se termina ordenando muchas pequeñas matrices que, a continuación, se combinan en matrices ordenadas más grandes.
Ejemplos
En el propio JDK de Java en la ruta .\sample\forkjoin\mergesort se pueden encontrar lo ficheros de ejemplo de Fork-Join. Son MergeDemo.java y MergeSort.java. Se pueden descargar desde este enlace.